One drawback of PDF file is that users can't directly extract the text or pictures in the document, which brings trouble for us to reuse the information that we find useful. This article demonstrates how to extract text and images from a PDF document by using Free Spire.PDF for Java.
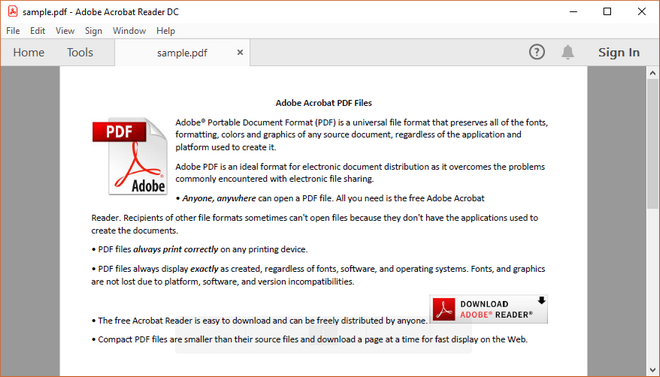
Below is a screenshot of the sample PDF document.
Installing Spire.Pdf.jar
If you create a Maven project, you can easily import the jar in your application using the following configurations. For non-Maven projects, download the jar file from this link and add it as a dependency in your application.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId> e-iceblue </groupId>
<artifactId>spire.pdf.free</artifactId>
<version>2.6.3</version>
</dependency>
</dependencies>
Example 1. Extract text
import java.io.FileWriter;
import java.io.IOException;
public class ExtractText {
public static void main(String[] args) {
//create a PdfDocument instance
PdfDocument doc = new
PdfDocument();
//load a sample PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\sample.pdf");
//create a StringBuilder instance
StringBuilder sb = new
StringBuilder();
//loop through PDF pages and extract text of each page
PdfPageBase page;
for (int i = 0; i < doc.getPages().getCount(); i++) {
page = doc.getPages().get(i);
sb.append(page.extractText(true));
}
FileWriter writer;
try {
//write text into a .txt file
writer = new FileWriter("C:\\Users\\Administrator\\Desktop\\ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
doc.close();
}
}

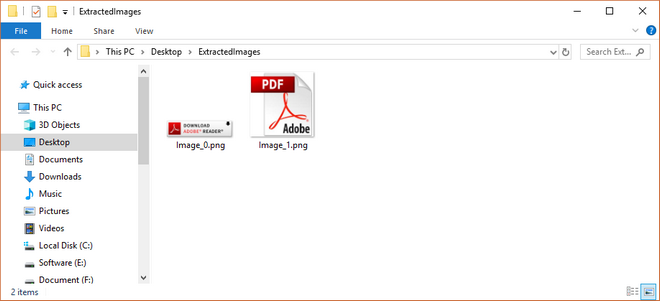
Example 2. Extract images
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import
java.io.IOException;
public class ExtractImage {
public static void main(String[] args) throws IOException {
//create a PdfDocment object
PdfDocument doc = new
PdfDocument();
//load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\sample.pdf");
//declare an int variable
int index = 0;
//loop through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
//extract images from a particular page
for (BufferedImage image : doc.getPages().get(i).extractImages()) {
//specify the file path and name
File output = new File("C:\\Users\\Administrator\\Desktop\\ExtractedImages\\" + String.format("Image_%d.png",
index++));
//save image as .png file
ImageIO.write(image,
"PNG", output);
}
}
}
}
Write a comment